

Formal definition[edit]
One commonly distinguishes between the relative error and the absolute error.
Given some value v and its approximation vapprox, the absolute error is
where the vertical bars denote the absolute value.
If the relative error is
and the percent error (an expression of the relative error) is
In words, the absolute error is the magnitude of the difference between the exact value and the approximation. The relative error is the absolute error divided by the magnitude of the exact value.
An error bound is an upper limit on the relative or absolute size of an approximation error.
Generalizationsedit
These definitions can be extended to the case when and are n-dimensional vectors, by replacing the absolute value with an n-norm.
Задача №3. Расчёт параметров регрессии и корреляции с помощью Excel
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
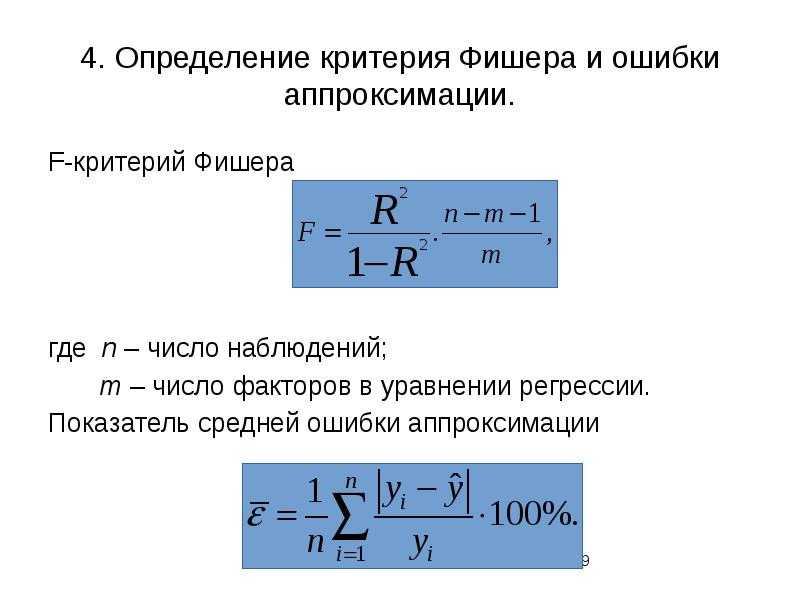
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.
Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессиивоспользуемся встроенной статистической функцией ЛИНЕЙН.
1) Откройте существующий файл, содержащий анализируемые данные; 2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики. 3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию. 4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;
Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.










Щёлкните по кнопке ОК;
Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R 2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов |
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
нескольких независимых
Examples[edit]
Best rational approximants for π (green circle), e (blue diamond), ϕ (pink oblong), (√3)/2 (grey hexagon), 1/√2 (red octagon) and 1/√3 (orange triangle) calculated from their continued fraction expansions, plotted as slopes y/x with errors from their true values (black dashes)
- v
- t
- e
As an example, if the exact value is 50 and the approximation is 49.9, then the absolute error is 0.1 and the relative error is 0.1/50 = 0.002 = 0.2%. Another example would be if, in measuring a 6 mL beaker, the value read was 5 mL. The correct reading being 6 mL, this means the percent error in that particular situation is, rounded, 16.7%.
The relative error is often used to compare approximations of numbers of widely differing size; for example, approximating the number 1,000 with an absolute error of 3 is, in most applications, much worse than approximating the number 1,000,000 with an absolute error of 3; in the first case the relative error is 0.003 and in the second it is only 0.000003.
There are two features of relative error that should be kept in mind. Firstly, relative error is undefined when the true value is zero as it appears in the denominator (see below). Secondly, relative error only makes sense when measured on a ratio scale, (i.e. a scale which has a true meaningful zero), otherwise it would be sensitive to the measurement units. For example, when an absolute error in a temperature measurement given in Celsius scale is 1 °C, and the true value is 2 °C, the relative error is 0.5, and the percent error is 50%. For this same case, when the temperature is given in Kelvin scale, the same 1 K absolute error with the same true value of 275.15 K gives a relative error of 3.63×10−3 and a percent error of only 0.363%. Celsius temperature is measured on an interval scale, whereas the Kelvin scale has a true zero and so is a ratio scale. Thus the relative error is not very meaningful.
Средняя ошибка аппроксимации в excel. Оценка качества уравнения регрессии
Где y x — расчетное значение по уравнению.
Значение средней ошибки аппроксимации до 15% свидетельствует о хорошо подобранной модели уравнения.
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
Требуется: 1. Для характеристики зависимости у от х рассчитать параметры следующих функций: а) линейной; б) степенной; в) показательной; г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель). 2. Оценить каждую модель через среднюю ошибку аппроксимации А ср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии . а) линейное уравнение регрессии; Использование графического метода . Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X. Совокупность точек результативного и факторного признаков называется полем корреляции .

На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер. Линейное уравнение регрессии имеет вид y = bx + a + ε Здесь ε — случайная ошибка (отклонение, возмущение). Причины существования случайной ошибки: 1. Невключение в регрессионную модель значимых объясняющих переменных; 2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры. 3. Неправильное описание структуры модели; 4. Неправильная функциональная спецификация; 5. Ошибки измерения. Так как отклонения ε i для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то: 1) по наблюдениям x i и y i можно получить только оценки параметров α и β 2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке; Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где e i – наблюдаемые значения (оценки) ошибок ε i , а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти. Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Получаем b = -0.35, a = 76.88 Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x y | y(x) | (y i -y cp) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии: y(45.1) = -0.35*45.1 + 76.88 = 61.28 y(59) = -0.35*59 + 76.88 = 56.47 . . .
Ошибка аппроксимации Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
F-статистики. Критерий Фишера.
3
Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2. 4
Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу. В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.










, а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
Аппроксимация в Excel статистических данных аналитической функцией.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.

2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.

О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
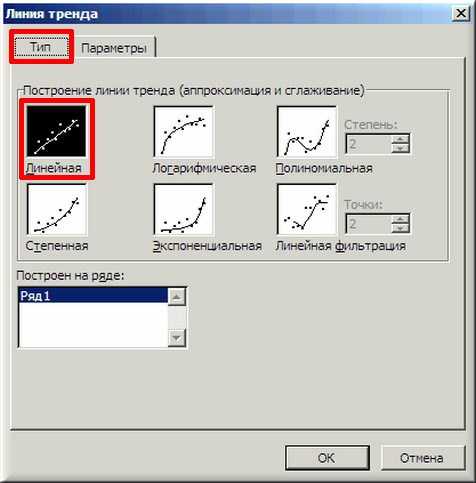
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».

6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.

Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R 2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
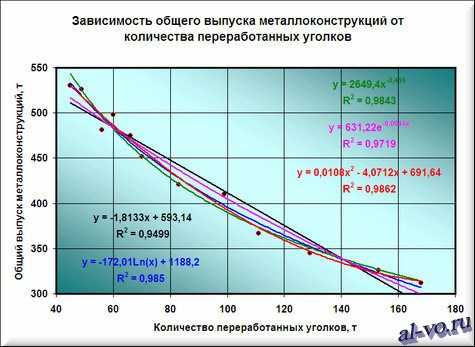
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R 2 .
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
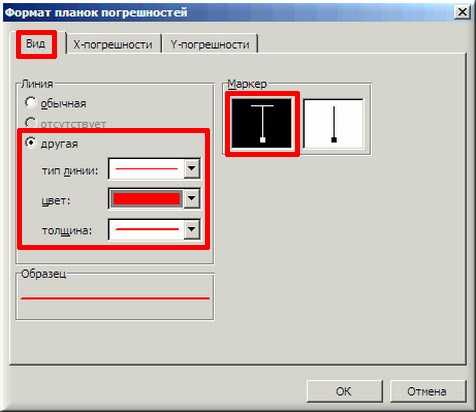
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
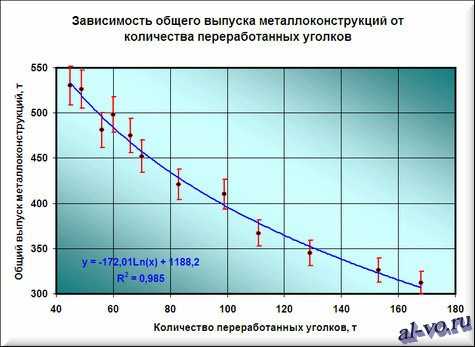
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
11kkii
Examples[edit]
Best rational approximants for π (green circle), e (blue diamond), ϕ (pink oblong), (√3)/2 (grey hexagon), 1/√2 (red octagon) and 1/√3 (orange triangle) calculated from their continued fraction expansions, plotted as slopes y/x with errors from their true values (black dashes)
- v
- t
- e
As an example, if the exact value is 50 and the approximation is 49.9, then the absolute error is 0.1 and the relative error is 0.1/50 = 0.002 = 0.2%. Another example would be if, in measuring a 6 mL beaker, the value read was 5 mL. The correct reading being 6 mL, this means the percent error in that particular situation is, rounded, 16.7%.









The relative error is often used to compare approximations of numbers of widely differing size; for example, approximating the number 1,000 with an absolute error of 3 is, in most applications, much worse than approximating the number 1,000,000 with an absolute error of 3; in the first case the relative error is 0.003 and in the second it is only 0.000003.
There are two features of relative error that should be kept in mind. Firstly, relative error is undefined when the true value is zero as it appears in the denominator (see below). Secondly, relative error only makes sense when measured on a ratio scale, (i.e. a scale which has a true meaningful zero), otherwise it would be sensitive to the measurement units. For example, when an absolute error in a temperature measurement given in Celsius scale is 1 °C, and the true value is 2 °C, the relative error is 0.5, and the percent error is 50%. For this same case, when the temperature is given in Kelvin scale, the same 1 K absolute error with the same true value of 275.15 K gives a relative error of 3.63×10−3 and a percent error of only 0.363%. Celsius temperature is measured on an interval scale, whereas the Kelvin scale has a true zero and so is a ratio scale. Thus the relative error is not very meaningful.
Formal definition[edit]
One commonly distinguishes between the relative error and the absolute error.
Given some value v and its approximation vapprox, the absolute error is
where the vertical bars denote the absolute value.
If the relative error is
and the percent error (an expression of the relative error) is
In words, the absolute error is the magnitude of the difference between the exact value and the approximation. The relative error is the absolute error divided by the magnitude of the exact value.
An error bound is an upper limit on the relative or absolute size of an approximation error.
Generalizationsedit
These definitions can be extended to the case when and are n-dimensional vectors, by replacing the absolute value with an n-norm.