Понятие и виды выборочного наблюдения
Выборочное наблюдение применяется, когда применение сплошного наблюдения физически невозможно из-за большого массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением, например, дегустация, испытание кирпичей на прочность и т.п.
Статистические единицы, отобранные для наблюдения, составляют выборочную совокупность или выборку, а весь их массив — генеральную совокупность (ГС). При этом число единиц в выборке обозначают n, а во всей ГС — N. Отношение n/N называется относительный размер или доля выборки.
Качество результатов выборочного наблюдения зависит от репрезентативности выборки, то есть от того, насколько она представительна в ГС. Для обеспечения репрезентативности выборки необходимо соблюдать принцип случайности отбора единиц, который предполагает, что на включение единицы ГС в выборку не может повлиять какой-либо иной фактор кроме случая.
Существует 4 способа случайного отбора в выборку:
- Собственно случайный отбор или «метод лото», когда статистическим величинам присваиваются порядковые номера, заносимые на определенные предметы (например, бочонки), которые затем перемешиваются в некоторой емкости (например, в мешке) и выбираются наугад. На практике этот способ осуществляют с помощью генератора случайных чисел или математических таблиц случайных чисел.
- Механический отбор, согласно которому отбирается каждая (N/n)-я величина генеральной совокупности. Например, если она содержит 100 000 величин, а требуется выбрать 1 000, то в выборку попадет каждая 100 000 / 1000 = 100-я величина. Причем, если они не ранжированы, то первая выбирается наугад из первой сотни, а номера других будут на сотню больше. Например, если первой оказалась единица № 19, то следующей должна быть № 119, затем № 219, затем № 319 и т.д. Если единицы генеральной совокупности ранжированы, то первой выбирается № 50, затем № 150, затем № 250 и так далее.
- Отбор величин из неоднородного массива данных ведется стратифицированным (расслоенным) способом, когда генеральная совокупность предварительно разбивается на однородные группы, к которым применяется случайный или механический отбор.
- Особый способ составления выборки представляет собой серийный отбор, при котором случайно или механически выбирают не отдельные величины, а их серии (последовательности с какого-то номера по какой-то подряд), внутри которых ведут сплошное наблюдение.
Качество выборочных наблюдений зависит и от типа выборки: повторная или бесповторная. При повторном отборе попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При этом у всех величин генеральной совокупности одинаковая вероятность включения в выборку.Бесповторный отбор означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку.
Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор.
Определение необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем теории вероятностей, которые позволяют установить, какой объем единиц следует выбрать из генеральной совокупности, чтобы он был достаточным и обеспечивал репрезентативность выборки.
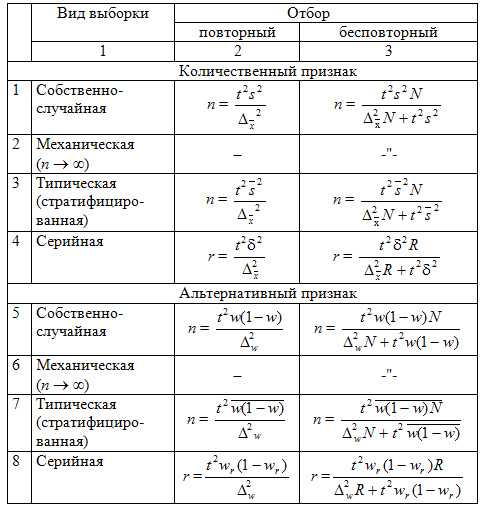
Уменьшение стандартной ошибки выборки, а следовательно, увеличение точности оценки всегда связано с увеличением объема выборки, поэтому уже на стадии организации выборочного наблюдения приходится решать вопрос о том, каков должен быть объем выборочной совокупности, чтобы была обеспечена требуемая точность результатов наблюдений. Расчет необходимого объема выборки строится с помощью формул, выведенных из формул предельных ошибок выборки (Δ), соответствующих тому или иному виду и способу отбора. Так, для случайного повторного объема выборки (n) имеем:
Суть этой формулы – в том, что при случайном повторном отборе необходимой численности объем выборки прямо пропорционален квадрату коэффициента доверия (t2) и дисперсии вариационного признака (σ2) и обратно пропорционален квадрату предельной ошибки выборки (σ2). В частности, с увеличением предельной ошибки в два раза необходимая численность выборки может быть уменьшена в четыре раза. Из трех параметров два (t и σ) задаются исследователем. При этом исследователь исходя из цели
и задач выборочного обследования должен решить вопрос: в каком количественном сочетании лучше включить эти параметры для обеспечения оптимального варианта? В одном случае его может больше устраивать надежность полученных результатов (t), нежели мера точности (σ), в другом – наоборот. Сложнее решить вопрос в отношении величины предельной ошибки выборки, так как этим показателем исследователь на стадии проектировки выборочного наблюдения не располагает, поэтому в практике принято задавать величину предельной ошибки выборки, как правило, в пределах до 10 % предполагаемого среднего уровня признака. К установлению предполагаемого среднего уровня можно подходить по разному: использовать данные подобных ранее проведенных обследований или же воспользоваться данными основы выборки и произвести небольшую пробную выборку.
Наиболее сложно установить при проектировании выборочного наблюдения третий параметр в формуле (5.2) – дисперсию выборочной совокупности. В этом случае необходимо использовать всю информацию, имеющуюся в распоряжении исследователя, полученную в ранее проведенных подобных и пробных обследованиях.
Вопрос об определении необходимой численности выборки усложняется, если выборочное обследование предполагает изучение нескольких признаков единиц отбора. В этом случае средние уровни каждого из признаков и их вариация, как правило, различны, и поэтому решить вопрос о том, дисперсии какого из признаков отдать предпочтение, возможно лишь с учетом цели и задач обследования.
При проектировании выборочного наблюдения предполагаются заранее заданная величина допустимой ошибки выборки в соответствии с задачами конкретного исследования и вероятность выводов по результатам наблюдения.
В целом формула предельной ошибки выборочной средней величины позволяет определять:
- величину возможных отклонений показателей генеральной совокупности от показателей выборочной совокупности;
- необходимую численность выборки, обеспечивающую требуемую точность, при которой пределы возможной ошибки не превысят некоторой заданной величины;
- вероятность того, что в проведенной выборке ошибка будет иметь заданный предел.
Определение численности выборки
Разрабатывая программу выборочного наблюдения, иногда задаются конкретным значением предельной ошибки с уровнем вероятности. Неизвестной остается минимальная численность выборки, обеспечивающая заданную точность. Ее можно получить из формул средней и предельной ошибок в зависимости от типа выборки. Так, подставляя и в и, решая ее относительно численности выборки, получим следующие формулы:
для повторной выборки n =
для бесповторной выборки n = .










Кроме того, при статистических величинах с количественными признаками надо знать и выборочную дисперсию, но к началу расчетов и она не известна. Поэтому она принимается приближенно одним из следующих способов (в приоритетном порядке):
- Берется из предыдущих выборочных наблюдений;
- Используется правило, согласно которому в размахе вариации укладывается примерно шесть стандартных отклонений (, а так как , то отсюда );
- Используется правило «трех сигм», согласно которому в средней величине укладывается примерно 3 стандартных отклонения (; отсюда ).
При изучении не численных признаков, если даже нет приблизительных сведений о выборочной доле, принимается w = 0,5, что по соответствует выборочной дисперсии в максимальном размере Дв = 0,5*(1-0,5) = 0,25.
Предыдущая лекция…Следующая лекция…
Другие статьи по данной теме:
- назад: Показатели вариации: понятие, виды, формулы для вычислений
- далее: Ряды динамики: понятие и классификация. Показатели уровней ряда
динамики. Примеры решения задач
Список использованных источников
- Белобородова С.С. и др. Теория статистики: Типовые задачи с контрольными заданиями.
Екатеринбург: Изд-во Урал. гос. экон. ун-та, 2001; - Минашкин В.Г. и др. Курс лекций по теории статистики. / Московский международный институт эконометрики,
информатики, финансов и права. — М., 2003; - Сизова Т.М. Статистика: Учебное пособие. – СПб.: СПб ГУИТМО, 2005;
- Фёдорова Л.Н., Фёдорова А.Е. Методические указания по написанию контрольной работы по курсу «Статистика»
для студентов экономических специальностей: УрГЭУ, 2007;
Выборочное наблюдение как источник статистической информации в социально-экономическом исследовании
Статистическое наблюдение может быть реализовано, как посредством полного охвата какой-то области, направления деятельности, включая все его составные компоненты, так и посредством проведения выборки определенных объектов, подлежащих изучению и анализу. В первом случае, статистическое исследование носит сплошной характер, а во втором случае – выборочный.
Определение 1
Выборочное наблюдение – это статистическое рассмотрение отдельных единиц исследуемой совокупности, которые отобраны случайным образом.
Выборочное наблюдение является методом, который позволяет сделать выводы о целой группе, основываясь на изучении только части этой группы. Для достижения точности результатов необходимо соблюдать все правила и принципы статистического наблюдения, а также научно организовать процесс отбора единиц для исследования. Этот метод позволяет экономить время и ресурсы, так как изучение всей совокупности может быть трудоемким и дорогостоящим. Выборочное наблюдение помогает получить общую характеристику группы, используя информацию, полученную из отобранных единиц. Таким образом, данный метод является важным инструментом для проведения статистических исследований.
Положительные аспекты проведения такого наблюдения:
Сокращение объема работ по сбору данных и ускорение их обработки являются ключевыми преимуществами данного метода, что позволяет получать статистическую информацию оперативно и с минимальными затратами на труд и ресурсы при проведении различных исследований.
Этот метод является единственно возможным во многих случаях, например, при контроле качества продукции, где проверка сопровождается уничтожением или разложением образцов для измерения сахаристости фруктов, содержания клейковины в печеном хлебе, проверки прочности ткани или износа обуви.
При соблюдении правил научной организации исследования данный метод также обеспечивает более точные результаты и может быть использован для проверки данных, полученных при сплошном учете. Например, при переписи населения часто проводятся выборочные контрольные обходы для проверки записей, полученных при сплошном наблюдении.
Минимальное количество обследуемых единиц позволяет провести исследование более тщательно и квалифицированно, что в свою очередь снижает вероятность возникновения ошибок при регистрации данных и непрохождении ими контроля на стадии первичной информации.
Выборочное обследование также позволяет с достаточной точностью определить возможные расхождения между показателями, полученными при сплошном и выборочном наблюдении. Таким образом, можно определить предельные отклонения фактических характеристик совокупности от полученных оценок
Это важно для анализа и оценки данных, полученных при выборочном обследовании, и их сравнения с данными, полученными при сплошном наблюдении.
Примеры решения задач по теме «Выборочное наблюдение в статистике»
Задача 1. Имеется информация о выпуске продукции (работ, услуг), полученной на основе 10%
выборочного наблюдения по предприятиям области:
 |
Определить: 1) по предприятиям, включенным в выборку: а) средний размер произведенной продукции на одно предприятие;
б) дисперсию объема производства; в) долю предприятий с объемом производства продукции более 400 тыс. руб.;
2) в целом по области с вероятностью 0,954 пределы, в которых можно ожидать: а) средний объем производства
продукции на одно предприятие; б) долю предприятий с объемом производства продукции более 400 тыс. руб.;
3) общий объем выпуска продукции по области.
Решение
Для решения задачи расширим предложенную таблицу.
 |
1) По предприятиям, включенным в выборку, средний размер произведенной продукции на одно предприятие
= 110800/400 = 277 тыс. руб.










Дисперсию объема производства вычислим упрощенным способом σ2 = 35640000/400 – 2772
= 89100 — 76229 = 12371.
Число предприятий, объем производства продукции которых превышает 400 тыс. руб. равно 36+12 = 48, а их доля
равна ω = 48:400 = 0,12 = 12%.
2) Из теории вероятности известно, что при вероятности Р=0,954 коэффициент доверия t=2. Предельная ошибка
выборки
= 2√12371:400 = 11,12 тыс. руб.
Установим границы генеральной средней: 277-11,12 ≤Хср≤ 277+11,12; 265,88 ≤Хср≤ 288,12
Предельная ошибка выборки доли предприятий
=2√0,12*0,88/400 = 0,03
Определим границы генеральной доли: 0,12-0,03≤ р ≤0,12+0,03; 0,09≤ р ≤0,15
3) Поскольку рассматриваемая группа предприятий составляет 10% от общего числа предприятий области, то в
целом по области насчитывается 4000 предприятий. Тогда общий объем выпуска продукции по области лежит в
пределах 265,88×4000≤Q≤288,12×4000; 1063520 ≤ Q ≤ 1152480
Задача 2. По результатам контрольной проверки налоговыми службами 400 бизнес-структур, у 140 из них в
налоговых декларациях не полностью указаны доходы, подлежащие налогообложению. Определите в генеральной
совокупности (по всему району) долю бизнес-структур, скрывших часть доходов от уплаты налогов, с вероятностью
0,954.
Решение
По условию задачи число единиц в выборочной совокупности n=400, число единиц, обладающих рассматриваемым признаком m=140,
вероятность Р=0,954.
Из теории вероятностей известно, что при вероятности Р=0,954 коэффициент доверия t=2.
Долю единиц, обладающих указанным признаком, определим по формуле: p=w+∆p, где w = m/n=140/400=0,35=35%,
а предельную ошибку признака ∆p получим из формулы: ∆p= t √w(1-w)/n = 2√0,35×0,65/400 ≈ 0,5 = 5%
Тогда р = 35±5%.
Ответ: Доля бизнес-структур, скрывших часть доходов от уплаты налогов с вероятностью 0,954 равна 35±5%.