
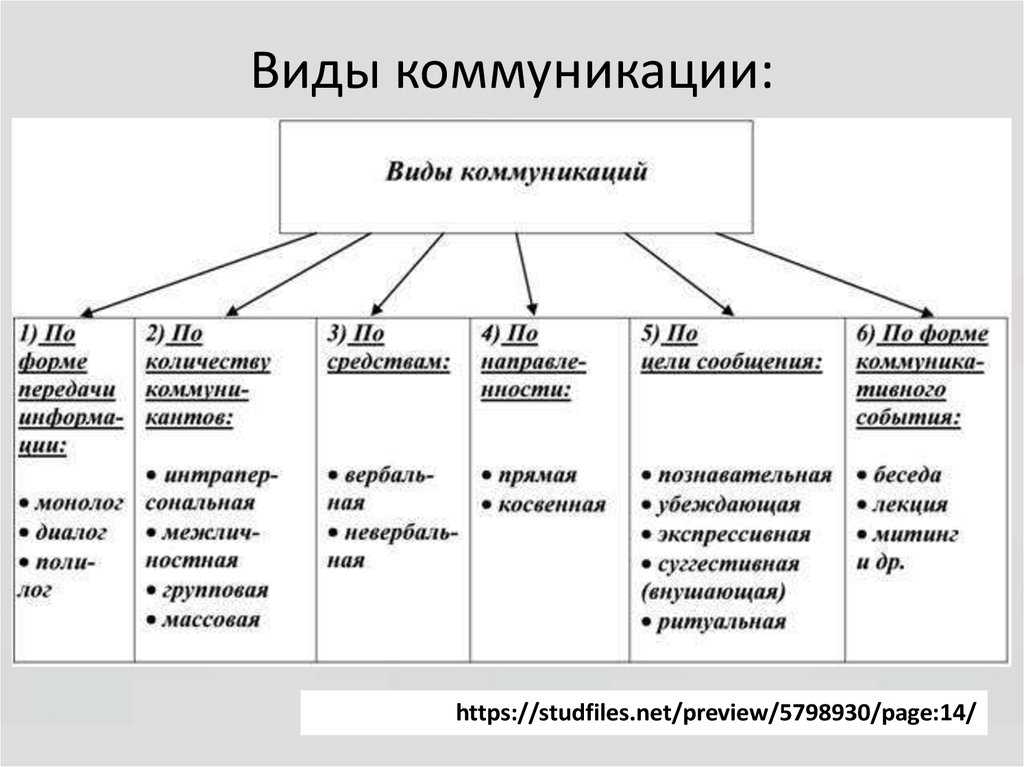
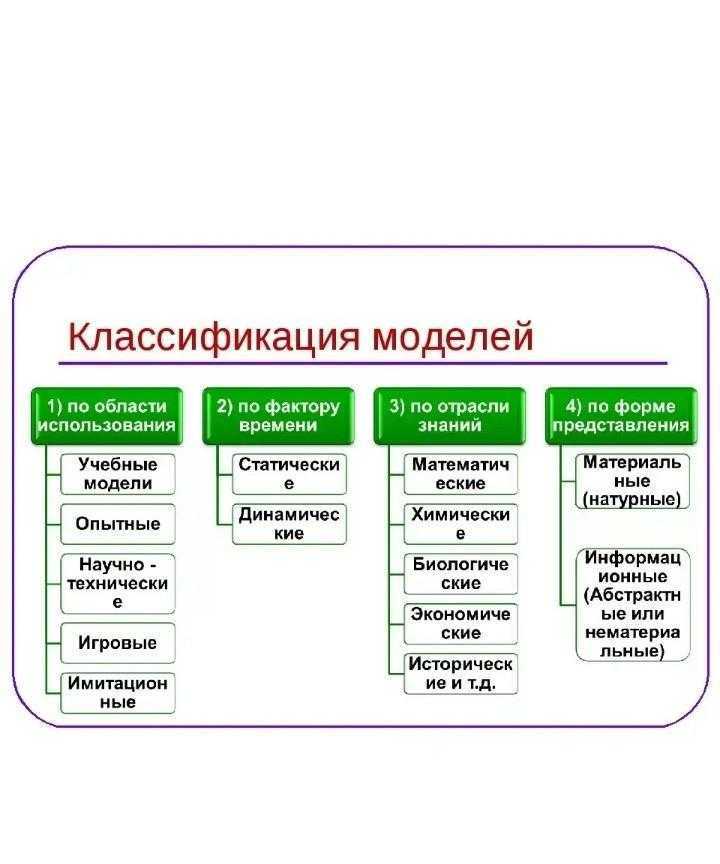
Что такое классификация?
Классификация — это процесс разделения объектов, явлений или сущностей на группы или категории в соответствии с определенными критериями. Процесс классификации позволяет упорядочить и систематизировать информацию, что облегчает ее использование и анализ.
Классификация применяется в различных областях человеческой деятельности, включая науку, бизнес, образование и другие. В науке классификация объектов может помочь установить общие закономерности и тенденции в поведении и их характеристиках. В бизнесе классификация продуктов может помочь определить целевую аудиторию, разработать стратегию продаж и распределить ресурсы. В образовании классификация позволяет систематизировать знания и определить принципы организации учебного процесса.
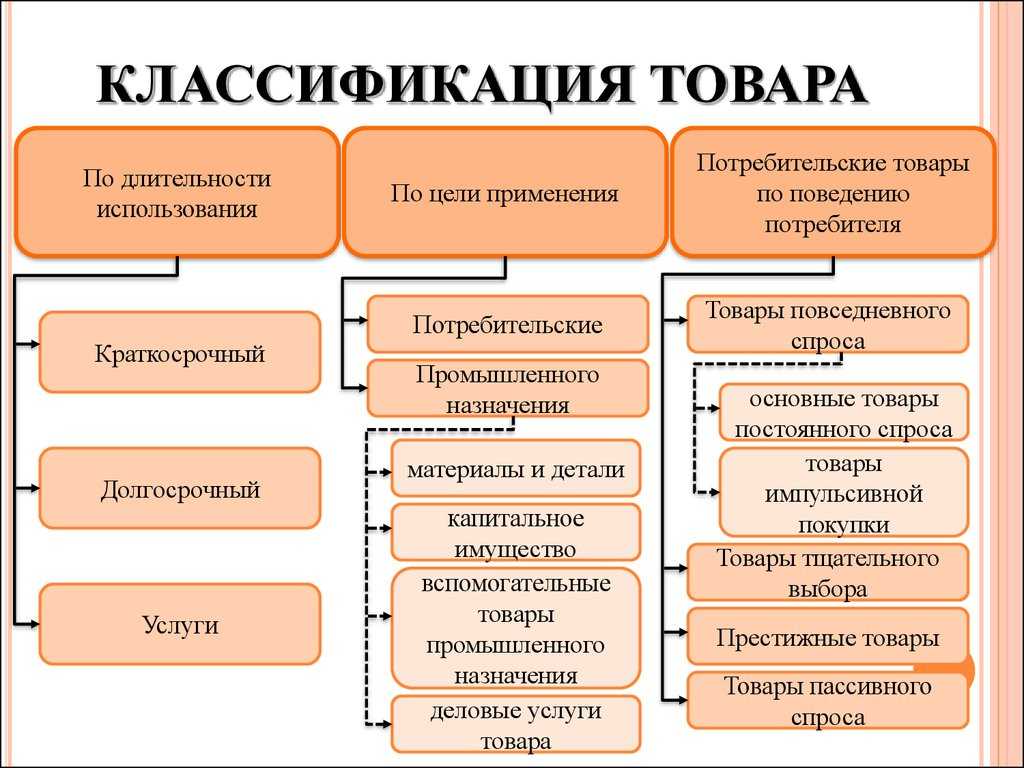
Для эффективной классификации необходимо выбрать критерии, по которым объекты будут разделены на группы. Критерии могут быть разными в зависимости от цели классификации и свойств объектов. Например, критерии классификации товаров в магазине могут включать цену, бренд, категорию товара и т.д. Необходимо также убедиться, что каждый объект может быть отнесен к только одной категории, чтобы избежать дублирования и ошибок.
В результате процесса классификации каждый объект будет отнесен к определенной группе или категории. Эти группы могут быть организованы иерархически, например, в виде дерева, что позволяет более детально описать свойства и отношения между группами объектов.
Примеры классификации в социологии и гуманитарных науках
Социология и гуманитарные науки широко используют классификацию в своих исследованиях. Одним из примеров классификации является деление людей на социальные классы на основе их экономического статуса. Эта классификация обычно включает верхний класс, средний класс и нижний класс. Каждый класс имеет свои характеристики, такие как уровень дохода, образование и профессиональный статус.
Другим примером классификации в социологии является классификация по возрасту. Люди могут делиться на группы, такие как дети, подростки, взрослые и пожилые люди. Каждая группа имеет свои собственные потребности и интересы, а также специфические вызовы и проблемы, которые они сталкиваются в различных этапах жизни.
Классификация также используется для описания социальных явлений, таких как преступность. Злоупотребление наркотиками, насилие и кражи могут быть классифицированы на разные типы и уровни серьезности. Эта классификация позволяет социологам и правоохранительным органам лучше понимать природу преступлений и разрабатывать более эффективные подходы к их предотвращению и раскрытию.
В гуманитарных науках классификация также широко используется для исследования языков, культур и литературы. Например, языки могут быть классифицированы на основе грамматических правил и фонетических особенностей. Литература может быть классифицирована по стилю и жанру, а культура — по этническому происхождению и региону.
Классификация является важным инструментом для глубокого изучения и понимания социальных явлений и культуры. Она позволяет исследователям более систематически и точно описывать и анализировать различные объекты и явления, что может привести к разработке более эффективных подходов и решений.
Определение и основные принципы
Классификация или систематизация – это процесс, который заключается в группировке объектов по определенным признакам. По этим признакам более крупные группы делаются менее разнородными, а более мелкие группы становятся более однородными.
Основной принцип классификации заключается в том, что объекты делятся на группы на основе одинаковых признаков. При выборе признаков нужно учитывать, чтобы они были значимыми для исследуемой области и позволяли разделить объекты на наиболее существенные категории. При этом каждому признаку должен соответствовать только один классификационный признак.
Еще один важный принцип – это иерархическая структура классификации. Объекты делятся на наименьшие группы, а затем из этих групп формируются более крупные. Это позволяет упорядочить классификацию и облегчить поиск и выбор объектов внутри классов.
Также к принципам классификации относятся процедуры проверки и оценки правильности классификации, которые используются для того, чтобы убедиться в правильности выбранных признаков и соответствия объектов определенным группам.
Наконец, стоит отметить, что правильность классификации зависит от выбранного набора признаков и может меняться в зависимости от расширения этого набора. Поэтому классификация должна быть гибкой и допускать возможность дополнения новыми признаками и категориями.
Что такое классификация и зачем она нужна
Классификация — это процесс разделения и организации объектов или явлений по сходству или различию в соответствии с определенными критериями. Она позволяет систематизировать информацию, упрощает ее поиск и анализ.
Классификация используется во многих областях, таких как наука, техника, бизнес, медицина и т.д. В науке, например, она помогает упорядочить знания и структурировать научные открытия. В бизнесе классификация используется для анализа рынка и конкурентной среды, выявления потенциальных потребителей и создания маркетинговых стратегий.
Классификационная система может быть представлена в виде таблиц, графиков, диаграмм, списков и т.д. Кроме того, она может иметь разные уровни сложности и детализации, в зависимости от целей и задач классификации.
Преимущества использования классификации:
- Упрощение работы с информацией и ее структурирование;
- Облегчение поиска необходимой информации;
- Позволяет быстро выявлять изменения и тренды;
- Облегчение принятия решений на основе анализа данных;
- Позволяет облегчить взаимодействие и обмен информацией в различных отраслях.
Таким образом, классификация позволяет организовать и структурировать информацию для ее более эффективного использования. Она играет важную роль в области науки, бизнеса, медицины, государства и других отраслях жизни.
Принципы классификации
Классификация – это процесс разделения объектов по определенным признакам. В информационных системах классификация используется для систематизации данных и облегчения поиска информации.
Основные принципы классификации:
- Принцип единства формы – все элементы классификации должны иметь одинаковую форму, т.е. состоять из определенных графических или текстовых элементов. Это облегчает восприятие и понимание информации.
- Принцип иерархии – все элементы классификации должны быть упорядочены в иерархическом порядке. Например, классификация стран может состоять из континентов, а континенты – из стран.
- Принцип исчерпывающей классификации – все объекты должны входить только в один класс. Это обеспечивает ясность и точность классификации и исключает неопределенность.
- Принцип доступности – классификация должна быть удобной для использования и быстрой для поиска нужной информации. Это достигается благодаря простоте и логичности классификационной схемы.
Примеры применения принципов классификации:
- Библиотечная классификация книг по тематике и жанру.
- Классификация продуктов в магазине по типу и производителю.
- Классификация документов в организации по виду и содержанию.
Принципы классификации облегчают задачу систематизации информации и позволяют быстро находить необходимую информацию. Однако, эффективность и удобство классификации зависят от правильности выбора критериев и наличия понятной и логичной системы.
Примеры классификации в естественных науках
Классификация – это важный инструмент в работе многих наук, включая естественные науки. Она позволяет упорядочить объекты и явления по определенным признакам и облегчить работу с ними. Рассмотрим несколько примеров классификации в естественных науках.
Биология: Одним из наиболее известных примеров классификации является древо жизни, которое разрабатывалось учеными на протяжении многих лет. Оно показывает эволюционные связи между разными видами живых существ и позволяет упорядочить их по уровням родства. Также в биологии классификацию используют для категоризации растительных и животных видов, формулирования законов наследственности и других задач.
Химия: Обширная область химии, связанная с классификацией элементов Периодической системы Менделеева. Первоначально система была создана для систематизации химических элементов, но со временем она стала широко применяться в различных научных и инженерных областях. В химии также используется классификация соединений по типам.
Физика: В физике многие концепции и теории опираются на классификацию объектов по разным признакам
Например, классификацию электромагнитного излучения по частоте имеет важное значение для понимания его воздействия на окружающую среду. Также в физике используют классификацию материалов по их свойствам, например, твердости, упругости и др
Всего лишь несколько примеров, показывающих, насколько важна классификация в естественных науках. Без систематизации и разделения объектов и явлений по определенным признакам, было бы крайне сложно проводить исследования и получать новые знания.
Алгоритм случайного леса
Случайный лес (Random Forest) — это один из самых популярных алгоритмов машинного обучения для задач классификации и регрессии. Это тип ансамбльных методов, который основан на использовании нескольких деревьев решений, объединенных в единый алгоритм.
Для обучения случайного леса необходимо подготовить набор данных из признаков и целевых переменных. Затем случайным образом выбираются примеры из этих данных, и на каждом таком наборе строится отдельное дерево решений.
При построении каждого дерева выбираются случайные признаки из набора, на основе которых будет производиться разбиение данных на две части. Затем выбирается наилучший признак и соответствующее значение для разделения данных. Процесс разбиения выполняется до тех пор, пока все листья дерева не будут соответствовать данным только одного класса.
Итоговый результат получается путем проведения голосования или усреднения результатов отдельных деревьев. Случайный лес показывает высокую точность классификации на разнообразных данных, а также обладает устойчивостью к переобучению и выбросам в данных.
Примеры использования алгоритма случайного леса включают в себя классификацию текстовых данных, распознавание образов и наблюдений в биологии, прогнозирование кликов на рекламные объявления и рейтинги кредитоспособности.
Примеры использования классификации в бизнесе
Классификация может быть полезна в ряде различных бизнес-задач. Например, классификация может использоваться для определения типов потребителей на основе их поведения и предпочтений. Это может помочь компаниям лучше понимать целевую аудиторию и отвечать на ее требования.
Классификация также может быть использована для определения категорий товаров и услуг на основе их основных характеристик, таких как цена, качество и функциональность. Это может помочь компаниям определить, какие продукты или услуги наиболее востребованы и какие следует улучшить или удалить из ассортимента.
Другим примером использования классификации в бизнесе является определение категорий продаж на основе общих характеристик их рентабельности. Это может помочь компаниям лучше понимать, какие продукты предпочитают их клиенты и какие виды продаж могут принести наибольшую прибыль.
- Классификация может быть полезна в ряде различных бизнес-задач
- Классификация может использоваться для определения типов потребителей
- Классификация может быть использована для определения категорий товаров и услуг
- Классификация может помочь определить наиболее востребованные продукты или услуги
- Классификация может помочь лучше понимать, какие продукты предпочитают клиенты и какие виды продаж могут принести наибольшую прибыль
Метод k ближайших соседей
Метод k ближайших соседей (k-NN) является одним из наиболее простых алгоритмов классификации. Он основан на идее о том, что объекты, близкие друг к другу по некоторым признакам, скорее всего принадлежат к одному классу.
Алгоритм k-NN определяет класс нового объекта, основываясь на классах k ближайших к нему объектов из обучающей выборки. При этом выбор метрики расстояния, используемой для определения близости объектов, играет важную роль в качестве классификации.
Одним из преимуществ метода k-NN является его простота в реализации и понимании. Кроме того, он хорошо справляется с классификацией нелинейных объектов и устойчив к шуму в данных. Однако, он может быть неэффективен при большом объеме выборки, так как требует хранения всей обучающей выборки.
Примером использования метода k-NN может быть классификация пациентов на основе их медицинских данных для выявления риска заболеваний. Также метод k-NN может использоваться в компьютерном зрении для распознавания образов и сравнения изображений.
- Преимущества: простота в реализации и понимании, устойчивость к шуму и эффективность при классификации нелинейных объектов.
- Недостатки: неэффективен при больших объемах выборки, зависимость от выбора метрики расстояния.
- Пример использования: классификация пациентов на основе медицинских данных, распознавание образов в компьютерном зрении.
Определение классификации (основное)
Если взять именно дословное определение, образованное от перевода латинских слов, то классификация — это “делать разряд”.
Таким образом, можно, подогнав перевод под нормы литературного русского языка, перевести этот термин, как возможность подразделять нечто общее на составные части, разбивать на разряды и, тем самым, упорядочивать предметы по свойствах и характеристикам, общим для них.
Деление видов на подвида, а также укрупнение нескольких видов в царство или семейство — вот моменты, стандартные для классификации в общепринятом смысле.
При этом, объединённые в одной видовой группе организмы или растения обладают множеством сходных признаков, которые и позволяют классифицировать их общность.
По описанным выше признакам можно сформулировать простое и понятное определение классификации. Можно утверждать, что это совокупность различных подгрупп чего-то общего, формально отличающихся друг от друга различными характеристиками и признаками, при этом по общим видовым признакам относящихся к единой большой группе.
К примеру, рассмотрим классификацию людей, формально разделить которых можно по тысячам характерных признаков, начиная с цвета кожи, физического состояния, возраста, пола, вероисповедания и заканчивая отношением к различным социально-экономическим формациям.
Несмотря на огромное количество классификаций, все они остаются людьми в самом общем смысле этого слова, тем самым принадлежа к единой огромной группе, разделяющейся на множество обособленных подкатегорий.
Машины опорных векторов
Машины опорных векторов (SVM) — это мощный алгоритм для классификации и регрессии, который использует метод опорных векторов для построения оптимальной гиперплоскости, разделяющей объекты разных классов. Эти алгоритмы считаются одними из наиболее точных и надежных в методах машинного обучения.
Работа SVM состоит в том, чтобы найти оптимальную гиперплоскость, которая максимально разделяет объекты разных классов. Для этого SVM использует метод опорных векторов: выбирает такую гиперплоскость, которая максимально удалена от объектов наиболее близких к ней.
Применение SVM может быть очень полезным в различных областях, таких как прогнозирование цен на акции, обнаружение мошеннических операций в финансовых транзакциях, классификация изображений и текстов, анализ генетических и клинических данных и т.д.
Хотя SVM являются мощным инструментом машинного обучения, они могут быть сложными для понимания и реализации. Для их применения необходимо иметь некоторые знания в области математики и программирования, а также более подробно изучить основные принципы работы SVM и их применения в конкретных задачах машинного обучения.
- Преимущества SVM:
- Высокая точность;
- Хорошая устойчивость к шумам и переобучению;
- Широкий спектр применений в различных областях;
- Эффективная работа в условиях высокой размерности данных.
- Недостатки SVM:
- Сложность реализации и понимания;
- Отсутствие подходящего решения для задач, где объекты имеют сложную взаимосвязь;
- Высокое время обучения при большом количестве данных.
Классификация: формальная постановка
Пусть — множество описаний объектов,
— конечное множество номеров (имён, меток) классов.
Существует неизвестная целевая зависимость — отображение
,
значения которой известны только на объектах конечной обучающей выборки
.
Требуется построить алгоритм
,
способный классифицировать произвольный объект
.
Вероятностная постановка задачи
Более общей считается вероятностная постановка задачи.
Предполагается, что множество пар «объект, класс»
является вероятностным пространством
с неизвестной вероятностной мерой .
Имеется конечная обучающая выборка наблюдений
,
сгенерированная согласно вероятностной мере .
Требуется построить алгоритм
,
способный классифицировать произвольный объект
.
Признаковое пространство
Признаком называется отображение
,
где
— множество допустимых значений признака.
Если заданы признаки
,
то вектор
называется признаковым описанием объекта
.
Признаковые описания допустимо отождествлять с самими объектами.
При этом множество
называют признаковым пространством.



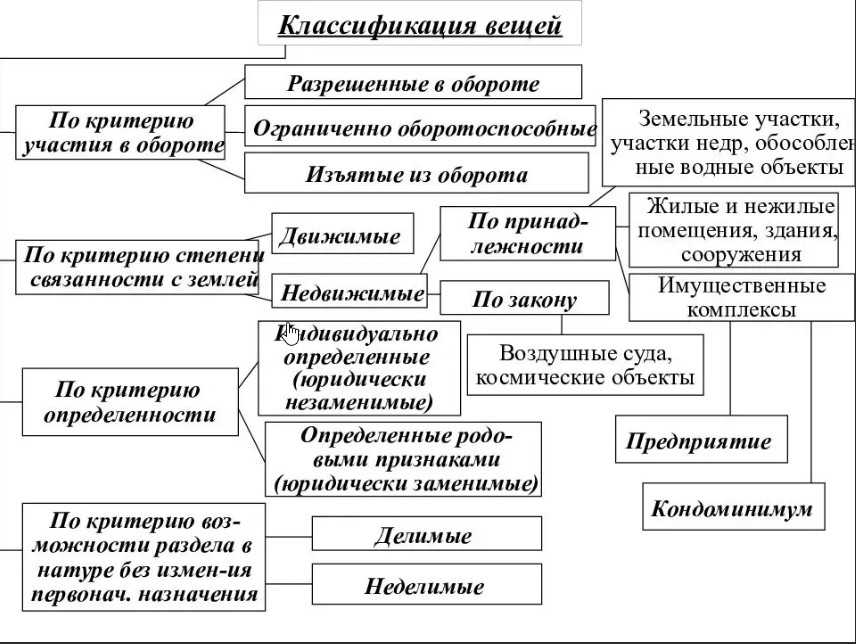
В зависимости от множества признаки делятся на следующие типы:
- бинарный признак: ;
- номинальный признак: — конечное множество;
- порядковый признак: — конечное упорядоченное множество;
- количественный признак: — множество действительных чисел.
Часто встречаются прикладные задачи с разнотипными признаками, для их решения подходят далеко не все методы.
Примеры прикладных задач
Задачи медицинской диагностики
В роли объектов выступают пациенты.
Признаки характеризуют результаты обследований, симптомы заболевания
и применявшиеся методы лечения.
Примеры бинарных признаков:
пол, наличие головной боли, слабости.
Порядковый признак — тяжесть состояния
(удовлетворительное, средней тяжести, тяжёлое, крайне тяжёлое).
Количественные признаки —
возраст, пульс, артериальное давление,
содержание гемоглобина в крови, доза препарата.
Признаковое описание пациента является, по сути дела,
формализованной историей болезни.
Накопив достаточное количество прецедентов в электронном виде,
можно решать различные задачи:
- классифицировать вид заболевания (дифференциальная диагностика);
- определять наиболее целесообразный способ лечения;
- предсказывать длительность и исход заболевания;
- оценивать риск осложнений;
- находить синдромы — наиболее характерные для данного заболевания совокупности симптомов.
Ценность такого рода систем в том, что они способны мгновенно
анализировать и обобщать огромное количество прецедентов —
возможность, недоступная специалисту-врачу.
Предсказание месторождений полезных ископаемых
Признаками являются данные геологической разведки.
Наличие или отсутствие тех или иных пород на территории района
кодируется бинарными признаками.
Физико-химические свойства этих пород могут описываться
как количественными, так и качественными признаками.
Обучающая выборка составляется из прецедентов двух классов:
районов известных месторождений
и похожих районов, в которых интересующее ископаемое обнаружено не было.
При поиске редких полезных ископаемых
количество объектов может оказаться намного меньше,
чем количество признаков.
В этой ситуации плохо работают классические статистические методы.
Задача решается путём
поиска закономерностей в имеющемся массиве данных.
В процессе решения выделяются короткие наборы признаков,
обладающие наибольшей информативностью —
способностью наилучшим образом разделять классы.
По аналогии с медицинской задачей,
можно сказать, что отыскиваются «синдромы» месторождений.
Это важный побочный результат исследования,
представляющий значительный интерес для геофизиков и геологов.
Оценивание кредитоспособности заёмщиков
Эта задача решается банками при выдаче кредитов.
Потребность в автоматизации процедуры выдачи кредитов впервые возникла
в период бума кредитных карт 60-70-х годов в США и других развитых странах.
Объектами в данном случае являются физические или юридические лица, претендующие на получение кредита.
В случае физических лиц признаковое описание состоит из анкеты,
которую заполняет сам заёмщик, и, возможно, дополнительной информации,
которую банк собирает о нём из собственных источников.
Примеры бинарных признаков: пол, наличие телефона.
Номинальные признаки — место проживания, профессия, работодатель.
Порядковые признаки — образование, занимаемая должность.
Количественные признаки —
сумма кредита, возраст, стаж работы, доход семьи,
размер задолженностей в других банках.
Обучающая выборка составляется из заёмщиков с известной кредитной историей.
В простейшем случае принятие решений
сводится к классификации заёмщиков на два класса:
«хороших» и «плохих».
Кредиты выдаются только заёмщикам первого класса.
В более сложном случае оценивается суммарное число баллов (score) заёмщика,
набранных по совокупности информативных признаков.
Чем выше оценка, тем более надёжным считается заёмщик.
Отсюда и название — кредитный скоринг.
На стадии обучения производится синтез и отбор информативных признаков
и определяется, сколько баллов назначать за каждый признак,
чтобы риск принимаемых решений был минимален.
Следующая задача — решить, на каких условиях выдавать кредит:
определить процентную ставку, срок погашения,
и прочие параметры кредитного договора.
Эта задача также может быть решения методами обучения по прецедентам.
Преимущества метода k ближайших соседей
Несмотря на
очевидные недостатки, метод k ближайших соседей получил широкое
распространение и в ряде задач показывает хорошие результаты. Главным его
преимуществом является простота реализации. Нам достаточно выделить k ближайших
объектов и выделить класс с максимальным числом представителей. Вычислительно,
это очень просто. Здесь даже нет, как такового, алгоритма обучения. Все, что
нам нужно – это иметь массив размеченных данных (представителей классов) и по
ним, затем, относить новые объекты к тому или иному классу. Это называется lazylearning (ленивое
обучение).
Благодаря
простоте реализации, мы можем на обучающей выборке применить технику
скользящего контроля leave-one-out (LOO) для нахождения
наилучшего параметра k. Я напомню, что при LOO мы
последовательно убираем из выборки по одному образу и оцениваем качество его
прогнозирования выбранной моделью (алгоритму классификации) по оставшейся
выборке. Так как наша модель в методе k ближайших соседей зависит от
параметра k:
то его можно подбирать
по методу LOO так, чтобы алгоритм
совершал как можно меньше ошибок:
Даже для больших
выборок в сотни тысяч и миллион наблюдений можно перебрать целые значения k, скажем в диапазоне
от 1 до 100 и выбрать тот, который даст минимум функции LOO.
Я, надеюсь, из
этого занятия вы поняли, что из себя в целом представляют метрические методы
классификации и как работает алгоритм k ближайших соседей.
Видео по теме
Машинное обучение. Начало
#1. Что такое машинное обучение? Обучающая выборка и признаковое пространство
#2. Постановка задачи машинного обучения
#3. Линейная модель. Понятие переобучения
#4. Способы оценивания степени переобучения моделей
#5. Уравнение гиперплоскости в задачах бинарной классификации
#6. Решение простой задачи бинарной классификации
#7. Функции потерь в задачах линейной бинарной классификации
#8. Стохастический градиентный спуск SGD и алгоритм SAG
#9. Пример использования SGD при бинарной классификации образов
#10. Оптимизаторы градиентных алгоритмов: RMSProp, AdaDelta, Adam, Nadam
#11. L2-регуляризатор. Математическое обоснование и пример работы
#12. L1-регуляризатор. Отличия между L1- и L2-регуляризаторами
#13. Логистическая регрессия. Вероятностный взгляд на машинное обучение
#14. Вероятностный взгляд на L1 и L2-регуляризаторы
#15. Формула Байеса при решении конкретных задач
#16. Байесовский вывод. Наивная байесовская классификация
#17. Гауссовский байесовский классификатор
#18. Линейный дискриминант Фишера
#19. Введение в метод опорных векторов (SVM)
#20. Реализация метода опорных векторов (SVM)
#21. Метод опорных векторов (SVM) с нелинейными ядрами
#22. Вероятностная оценка качества моделей
#23. Показатели precision и recall. F-мера



#24. Метрики качества ранжирования. ROC-кривая
#25. Метод главных компонент (Principal Component Analysis)
#26. Сокращение размерности признакового пространства с помощью PCA
#27. Сингулярное разложение и его связь с PCA
#28. Многоклассовая классификация. Методы one-vs-all и all-vs-all
#29. Метрические методы классификации. Метод k ближайших соседей
#30. Методы парзеновского окна и потенциальных функций
#31. Метрические регрессионные методы. Формула Надарая-Ватсона
#32. Задачи кластеризации. Постановка задачи
#33. Алгоритм кластеризации Ллойда (K-средних, K-means)
#34. Алгоритм кластеризации DBSCAN
#35. Агломеративная иерархическая кластеризация. Дендограмма
#36. Логические методы классификации
#37. Критерии качества для построения решающих деревьев
#38. Построение решающих деревьев жадным алгоритмом ID3
#39. Усечение (prunning) дерева, обработка пропусков и категориальных признаков
#40. Решающие деревья в задачах регрессии. Алгоритм CART
#41. Случайные деревья и случайный лес. Бутстрэп и бэггинг
#42. Введение в бустинг (boosting). Алгоритм AdaBoost при классификации
#43. Алгоритм AdaBoost в задачах регрессии
#44. Градиентный бустинг и стохастический градиентный бустинг
#45. Нейронные сети. Краткое введение в теорию
#46. Обучение нейронной сети. Алгоритм back propagation
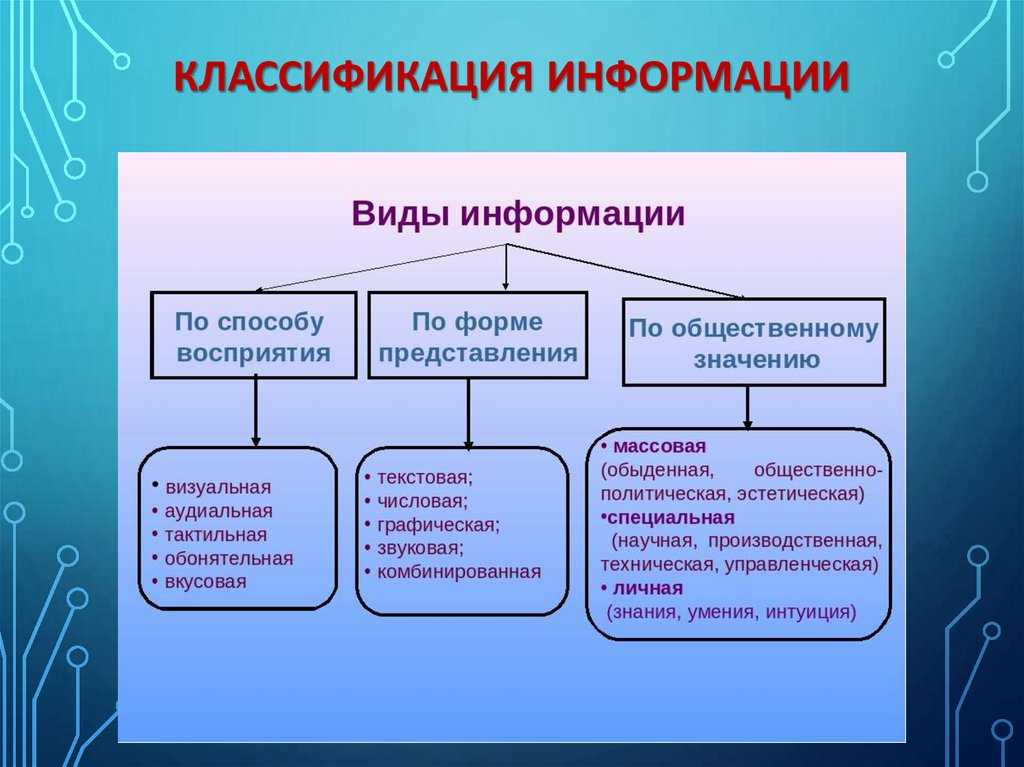
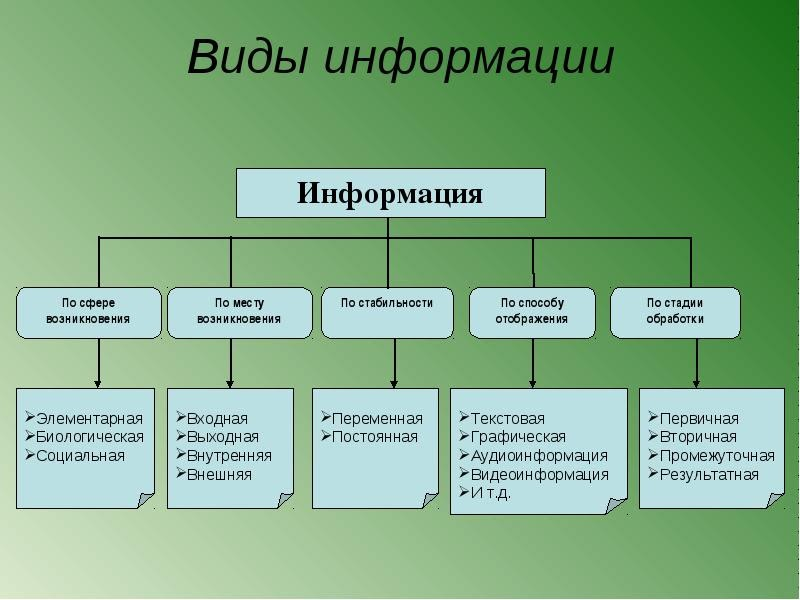
3 метода классификации информации
Существует три вида систем классификации информации: иерархическая, фасетная и дескрипторная. Отличаются они тем, что в них по-разному используются классификационные параметры.
Иерархическая система
Отличительные черты:
- Строгая структурированность (количество классификационных признаков имеет большое значение).
- Объект на любом из уровней может быть причислен лишь к одному классу.
- Для распределения по группам на каждом из следующих уровней необходимо иметь информацию о классификационных признаках (соответствующих данному уровню) и их толкованиях.
- Глубина классификации определяется количеством определенных для нее уровней.
Узнай, какие ИТ — профессии входят в ТОП-30 с доходом от 210 000 ₽/мес
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в
IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее
будущее!
Скачивайте и используйте уже сегодня:
Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 21876
Преимущества:
- Метод прост.
- Большой плюс в том, что на разных ступенях иерархии в структуре задействуются независимые классификационные признаки.
Отрицательные моменты:
- Структура достаточно жёсткая.
- Если объект обладает признаками, которые заранее не были предусмотрены, то его невозможно будет отнести ни к одной из групп.
Фасетная система классификации информации
«Facet» в переводе с английского – «рамка».
Тут можно определять никак не связанные между собой признаки классификации и отталкиваться от их семантики. Фасеты – это и есть критерии классификации.





| Фасет 1 | Фасет 2 | Фасет 3 | Фасет 4 |
| … | … | … | … |
Отличительные черты:
- В процессе каждый из классифицируемых объектов наделяется определенным значением из фасета. Какие-то из рамок могут остаться неиспользованными.
- Каждый объект причисляется к конкретной группировке.
- В созданной системе этого вида значения рамок не должны повторяться.
- Каждый из фасетов в любой момент можно видоизменять, тем самым преобразовав и систему в целом.
Фасетная система классификации информации
Преимущества:
- Внедрение большого числа характеристик для классификации.
- Возможность преобразования всей системы с сохранением структуры созданных групп.
Отрицательные моменты:
Систему довольно трудно выстраивать из-за большого числа критериев классификации.
Дескрипторная система
Применяется в случаях, когда классификация объектов осуществляется на естественном языке. Например, в библиотечном деле.
Суть процесса:
- Собираются слова или словосочетания (в том числе синонимы), подходящие для описания конкретной области.
- Далее в отношении этих слов выполняется нормализация, то есть, выявляется одно или несколько самых часто используемых.
- Таким образом собирается словарь дескрипторов.
Для того чтобы собирать информацию по более широким областям, между дескрипторами специально выискиваются связи, которые могут быть следующих трех типов:
- синонимические (студент – ученик – обучающийся);
- родовидовые (университет – факультет – кафедра);
- ассоциативные (слушатель – учеба – аудитория – занятие).
Важность различения классификации и видов
Классификация и виды – два термина, которые часто используются в различных областях, включая науку и технологии. Но, несмотря на то, что эти термины похожи, они имеют существенные различия.
Классификация – это процесс, который позволяет организовать объекты в определенный порядок или систему на основе их общих характеристик. В то же время, виды относятся к конкретным группам объектов, которые имеют определенные общие признаки и свойства.
Различение между классификацией и видами важно, потому что это позволяет более точно определить объекты и организовать их в порядок. Это особенно важно в науке и технологиях, где точное определение и организация объектов может иметь важные последствия
Например, в биологии виды могут использоваться для определения родственных отношений между различными организмами. В инженерии классификация может использоваться для технического описания процессов и систем. Кроме того, точное различение между классификацией и видами может помочь улучшить качество обучения, поскольку это позволяет более точно определить цели и организовать учебный материал.
В итоге, понимание различий между классификацией и видами позволяет улучшить организацию объектов и процессов в науке, технологиях, образовании и других областях.
Виды: понятие и их характеристики
Виды — это группы живых организмов, которые имеют общие признаки и отличаются от других групп. Виды характеризуются морфологическими, физиологическими и генетическими особенностями.
Одним из важнейших признаков вида является способность к размножению. Виды, как правило, могут скрещиваться и давать потомство, которое также является представителями того же вида. В то же время, различные виды не могут скрещиваться между собой и давать плодовитое потомство.
Кроме того, виды могут иметь различные адаптации к своим условиям среды обитания, например, особые формы тела, окраски, поведенческие особенности, что позволяет им выживать в своей среде и конкурировать с другими организмами.
Виды играют важную роль в биологическом разнообразии, представляя собой уникальные биологические единицы и являясь основой для систематики и классификации живых организмов.
- Виды — это категория классификации, используемая для группировки и определения организмов по общим признакам. Они позволяют биологам лучше понимать и описывать природу и ее бесконечное разнообразие.
- Видовое разнообразие — это одна из основных составляющих биологического разнообразия, которое является наследием человечества.