

Стратегии построения групп[]
Отбор групп для их участия в психологическом эксперименте осуществляется с помощью различных стратегий, которые нужны для того, чтобы обеспечить максимально возможное соблюдение внутренней и внешней валидности.
- (случайный отбор)
- Привлечение реальных групп
Рандомизация
Рандомизация, или случайный отбор, используется для создания простых случайных выборок. Использование такой выборки основывается на предположении, что каждый член популяции с равной вероятностью может попасть в выборку. Например, чтобы сделать случайную выборку из 100 студентов вуза, можно сложить бумажки с именами всех студентов вуза в шляпу, а затем достать из неё 100 бумажек — это будет случайным отбором (Гудвин Дж., с. 147).
Попарный отбор
Попарный отбор — стратегия построения групп выборки, при котором группы испытуемых составляются из субъектов, эквивалентных по значимым для эксперимента побочным параметрам. Данная стратегия эффективна для экспериментов с использованием экспериментальных и контрольных групп с лучшим вариантом — привлечением близнецовых пар (моно- и дизиготных), так как позволяет создать .
Стратометрический отбор
Стратометрический отбор — рандомизация с выделением страт (или кластеров). При данном способе формирования выборки генеральная совокупность делится на группы (страты), обладающие определёнными характеристиками (пол, возраст, политические предпочтения, образование, уровень доходов и др.), и отбираются испытуемые с соответствующими характеристиками.
Приближённое моделирование
Приближённое моделирование — составление ограниченных выборок и обобщение выводов об этой выборке на более широкую популяцию. Например, при участии в исследовании студентов 2-го курса университета, данные этого исследования распространяются на «людей в возрасте от 17 до 21 года». Допустимость подобных обобщений крайне ограничена.
Вероятностная модель порождения данных
Случайная выборка
Вероятностная модель порождения данных предполагает, что выборка из генеральной совокупности формируется случайным образом.
Объём (длина) выборки считается произвольной, но фиксированной, неслучайной величиной.
Формально это означает, что с генеральной совокупностью связывается вероятностное пространство ,
где
— множество всех выборок длины ,
— заданная на этом множестве сигма-алгебра событий,
— вероятностная мера, как правило, неизвестная.
Случайная выборка — это последовательность из прецедентов, выбранная из множества согласно вероятностной мере .
Однородная выборка
Выборка называется однородной, если все её прецеденты одинаково распределёны, то есть выбраны из одного и того же распределения .
Независимая выборка
Выборка называется независимой, если вероятностная мера на представима в виде произведения вероятностных мер на , то есть
для любой системы подмножеств
Если на существует плотность распределения , то независимость означает, что -мерная плотность распределения на представима в виде произведения одномерных плотностей:
Простая выборка
Простая выборка — это случайная, однородная, независимая выборка (i.i.d. — independent, identically distributed).
Эквивалентное определение: выборка простая, если значения являются реализациями независимых одинаково распределённых случайных величин.
Простая выборка является математической моделью серии независимых опытов.
На гипотезу простой выборки существенно опираются многие методы
статистического анализа данных и
машинного обучения,
в частности,
большинство статистических тестов,
а также
оценки обобщающей способности
в теории вычислительного обучения.
Также существует множество методов, не предполагающих однородность и/или независимость выборки,
в частности, в теории случайных процессов, в прогнозировании временных рядов.
Метод максимума правдоподобия позволяет оценивать значения параметров модели по обучающей выборке,
в общем случае не требуя, чтобы выборка была однородной и независимой.
Однако в случае простых выборок применение метода существенно упрощается.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.
Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:
При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:
Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:

Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):








(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Основные определения
Понятие выборки используется, когда надо изучить какие-либо свойства совокупности объектов. Свойства объектов можно разделить на качественные и количественные.
Пример 1
Пусть нам необходимо изучить совокупность партии сметаны. Тогда качественным признаком может служить срок её годности, а количественным процент содержания жиров в данной сметане.
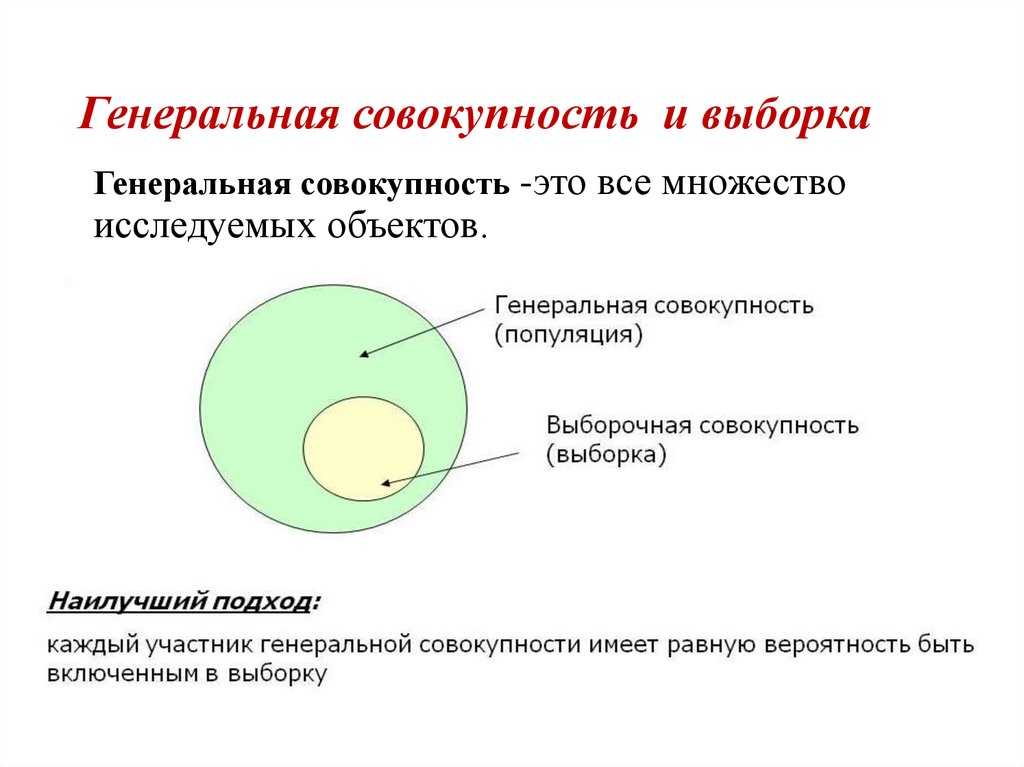
Совокупность или выборка может быть разделена на генеральную и выборочную.
Определение 1
Генеральная совокупность — совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Выборочная совокупность — часть отобранных объектов из генеральной совокупности.
С понятием совокупности также связано понятие объема данной совокупности.
Определение 3
Объем совокупности — число объектов этой совокупности.
Понятие объема совокупности относится и к выборочной, и к генеральной совокупности.
Пример 2
Пусть из партии 100 пачек масла для исследования выбрано 10 пачек. Тогда объем генеральной совокупности $N=100$, а объем выборки $n=10$.
Примечание 1
Исходя из первых двух определений, очевидно, что всегда выполняется неравенство $N>n$
Помимо этих двух совокупностей выделяют также репрезентативную или представительную выборку.
Определение 4
Репрезентативная (представительная) выборка — выборка, в которой все объекты выбраны случайно и генеральной совокупности, то есть каждый объект генеральной совокупности имеет одинаковую вероятность попасть в выборку.
Выборка также может быть повторной и бесповторной.
Определение 5
Повторная выборка — выборка, при которой выбранный объект возвращается обратно в генеральную совокупность перед выбором следующего объекта для исследования.
Определение 6
Бесповторная выборка — выборка, при которой объект не возвращается обратно в генеральную совокупность перед выбором очередного объекта для исследования.
Как выбирать?
Есть несколько способов собрать репрезентативную выборку.
Простая случайная выборка (simple random sample)
Случайным образом выбираем объекты нашей генеральной совокупности. При этом чем больше случайных объектов выбираем, тем лучше наша выборка отражает свойства генеральной совокупности
На Примере 2: Идем на детскую площадку и опрашиваем всех, кто там есть. В результате получится, что среди опрошенных будут дети разного пола и возраста в разной пропорции. Например, мы спросили о любимом мультфильме мальчика пяти лет, девочку трех лет, девочку четырех лет, мальчика двух лет и.т.д.
Стратифицированная выборка (stratified sample)
- Разделяем нашу генеральную совокупность на группы (страты) на основе определенного признака/признаков.
- Чтобы эти группы были равновероятно представлены в выборке, берем случайным образом элементы из каждой группы с равной вероятностью.
На Примере 2: делим детей по возрасту и полу, «идем» в группу «мальчики 5 лет» , случайно опрашиваем представителя данной группы, потом идет ко множеству «девочки 3 лет», случайно опрашиваем представительницу этой группы и т.д.
В таблице суммируются принципиальные различия между случайной и стратифицированной выборками:
| Простая случайная выборка | Стратифицированная выборка |
| Выбираем элементы из генеральной совокупности случайным образом | Выбираем элементы из каждой группы (страты) |
| Чем больше берем элементов из генеральной совокупности, тем лучше наша выборка отражает особенности генеральной совокупности | Мы уже на основе определенных признаков разделили нашу генеральную совокупность, добавляем в каждую подгруппу по примерно равному количеству элементов. Так наша выборка будет хорошо отражать особенности генеральной совокупности |
Групповая выборка (cluster sample)
- Делим нашу генеральную совокупность на группы, но эти группы должны быть относительно похожи между собой (в качестве примера можем взять районы Москвы и считать, что в них примерно одинаковое число жителей)
- Выбираем только некоторые группы, которые нас интересуют.
- Из выбранных групп выбираем случайным образом элементы.
Чтобы еще лучше понять, чем отличается стратифицированная выборка от групповой, рассмотрим таблицу:
| Стратифицированная выборка | Групповая выборка |
| Выбираем элементы из каждой группы (страты) | Выбираем элементы только из выбранных групп (страт) |
| Внутри группы элементы однородны, а между группами элементы различаются | В пределах группы элементы разнородны, но при этом все группы имеют схожесть |
| Схема выборки для всех групп одна | Схема выборки нужна только для выбранных групп |
| Повышает точность | Повышает эффективность выборки, уменьшая стоимость |
Сбор репрезентативной выборки — это нетривиальная задача, которая включает в себя выбор метода сбора и параметров сбора (например, подбор страт). Аккуратно собранная выборка — обязательное условие для проведения дальнейшего исследования
Использование нерепрезентативных данных приводит к ложным или неполным выводам, поэтому крайне важно обращать внимание, на каких данных проводилось то или иное исследование
Зависимые и независимые выборки[]
При сравнении двух (и более) выборок важным параметром является их зависимость. Если можно установить гомоморфную пару (то есть, когда одному случаю из выборки X сооветствует один и только один случай из выборки Y и наоборот) для каждого случая в двух выборках (и это основание взаимосвязи является важным для измеряемого на выборках признака), такие выборки называются зависимыми. Примеры зависимых выборок:
- пары близнецов,
- два измерения какого-либо признака до и после экспериментального воздействия,
- мужья и жёны
- и т. п.
В случае, если такая взаимосвязь между выборками отсутствует, то эти выборки считаются независимыми, например:
- мужчины и женщины,
- психологи и математики.
Соответственно, зависимые выборки всегда имеют одинаковый объём, а объём независимых может отличаться.
Сравнение выборок производится с помощью различных статистических критериев:
- t-критерий Стьюдента
- T-критерий Вилкоксона
- U-критерий Манна-Уитни
- Критерий знаков
- и др.
Репрезентативность[]
Выборка может рассматриваться в качестве репрезентативной или нерепрезентативной.
Пример нерепрезентативной выборки
В США одним из наиболее известных исторических примеров нерепрезентативной выборки считается случай, происшедший во время президентских выборов в 1936 году. Журнал «Литрери Дайджест», успешно прогнозировавший события нескольких предшествующих выборов, ошибся в своих предсказаниях, разослав десять миллионов пробных бюллетеней своим подписчикам, людям, выбранным по телефонным книгам всей страны, и людям из регистрационных списков автомобилей. В 25 % вернувшихся бюллетеней (почти 2,5 миллиона) голоса были распределены следующим образом:







- 57 % отдавали предпочтение кандидату-республиканцу Альфу Лэндону
- 40 % выбрали действующего в то время президента-демократа Франклина Рузвельта
На действительных же выборах, как известно, победил Рузвельт, набрав более 60 % голосов.
Ошибка «Литрери Дайджест» заключалась в следующем: желая увеличить репрезентативность выборки, — так как им было известно, что большинство их подписчиков считают себя республиканцами, — они расширили выборку за счёт людей, выбранных из телефонных книг и регистрационных списков. Однако они не учли современных им реалий и в действительности набрали ещё больше республиканцев: во время Великой депрессии обладать телефонами и автомобилями могли себе позволить в основном представители среднего и верхнего класса (то есть большинство республиканцев, а не демократов).
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
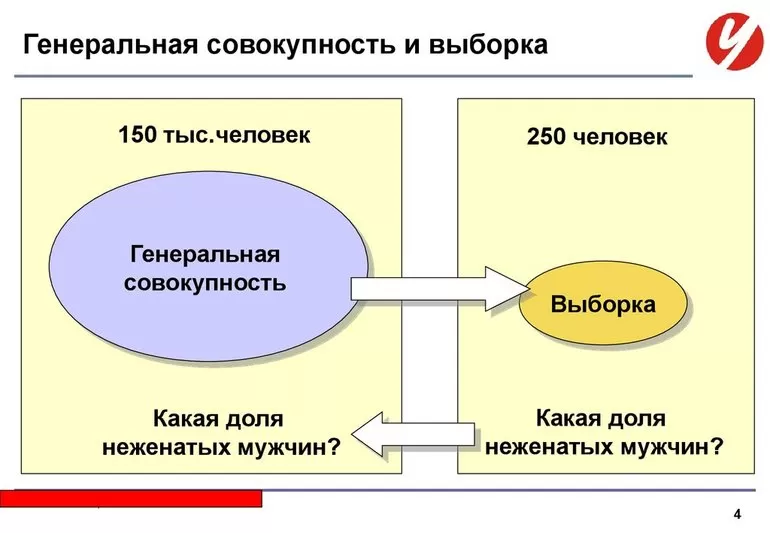
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Понятие выборки в социологическом исследовании
Определение 1
Социологическое исследование представляет собой научное исследование, основной целью которого является получение определенного знания. Другими словами, социологическое исследование это определение и обобщение социальных фактов при помощи прямой или косвенной регистрации событий, которые являются свойственными для исследуемых социальных явлений, объектов, а также взаимоотношений.
Благодаря социологическим исследованиям можно абсолютно по-другому подойти к исследованию социальных и экономически процессов в каком-либо регионе, а также обществе в целом.
Выборкой в социологическом исследовании традиционно принято называть:
- Совокупность компонентов объекта социологического исследования, которые подлежат непосредственному исследованию;
- Совокупность методов и процедур отбора компонентов объекта, единиц наблюдения и исследования при обширных социологических исследованиях.
Основная особенность социологических исследований заключается в том, что они являются не простым сбором, либо сбором каких-либо социальных фактов (в данном случае отбор будет являться субъективным), а является некой научной процедурой, в рамках которой применяются определенные социологические методы сбора самых различных сведений, а также используются специальные социологические технологии, к которым относится организация выборки.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.
Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Обучающая и тестовая выборка
Обучающая выборка (training sample) — выборка, по которой производится настройка (оптимизация параметров) модели зависимости.
Если модель зависимости построена по обучающей выборке , то оценка качества этой модели, сделанная по той же выборке оказывается, как правило, оптимистически смещённой.
Это нежелательное явление называют переобучением.
На практике оно встречается очень часто.
Хорошую эмпирическую оценку качества построенной модели даёт её проверка на независимых данных, которые не использовались для обучения.
Тестовая (или контрольная) выборка (test sample) — выборка, по которой оценивается качество построенной модели. Если обучающая и тестовая выборки независимы, то оценка, сделанная по тестовой выборке, является несмещённой.
Оценку качества, сделанную по тестовой выборке, можно применить для выбора наилучшей модели.
Однако тогда она снова окажется оптимистически смещённой.
Для получения немсещённой оценки выбранной модели приходится выделять третью выборку.
Проверочная выборка (validation sample) — выборка, по которой осуществляется выбор наилучшей модели из множества моделей, построенных по обучающей выборке.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны
Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:










6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Основные виды выборок в социологическом исследовании
На сегодняшний день основными видами выборки в социологических исследованиях являются следующие их виды:
Стихийная выборка. Здесь опрашиваются респонденты, которые являются наиболее доступными. Основными примерами стихийных выборок являются опросы в газетах или журналах, анкеты, которые были переданы респондентам на само заполнение, а также Интернет-опросы. Размер и состав стихийных выборок заранее является не известным. Он выявляется таким показателем, как активность респондентов;
Случайная выборка. Данный вид выборки является одним из наиболее строгих видов. В его основе лежит принцип вероятностного отбора. Основным условием возможности данного отбора является доступность для исследователя каждого из имеющихся компонентов генеральной совокупности. Из-за этого случайная выборка осуществляется только на довольно небольших по объему генеральных совокупностях, или уже на заключительном этапе отбора;
Механическая выборка. Данный вид выборки основывается на том, что традиционно отбор единиц в выборочную совокупность из генеральной, которая традиционно разбивается по какому-либо нейтральному признаку на одинаковые промежутки, происходит таким образом, что из каждой группы в выборку выбирается только одна единица;
Гнездовая выборка. Это такой вид выборки, при котором выбираемые объекты являются группой или гнездом более мелких единиц. Гнездо в свою очередь является единицей отбора высшей ступени, которая включает в себя более мелкие единицы низшей ступени. Примером гнезда могут являться населенные пункты, районы, дома и многое другое;
Квотная выборка. В данном случае отбор респондентов происходит целенаправленно
При этом важно соблюдать параметры квоты;
Многоступенчатая выборка. В данном случае отбор происходит в несколько этапов
Например, сначала выбираются в каком-либо городе предприятие, на предприятии выбирается цех, а уже непосредственно в цехах подбираются респонденты.
Генеральная совокупность
Давайте разберемся, на что в первую очередь обращать внимание перед началом любой исследовательской или аналитической работы, какие вообще данные следует использовать,
Для начала нам нужно четко обозначить, для какого множества объектов мы хотели бы получить результаты экспериментов или исследований. То есть, что мы будем считать генеральной совокупностью нашего исследования.
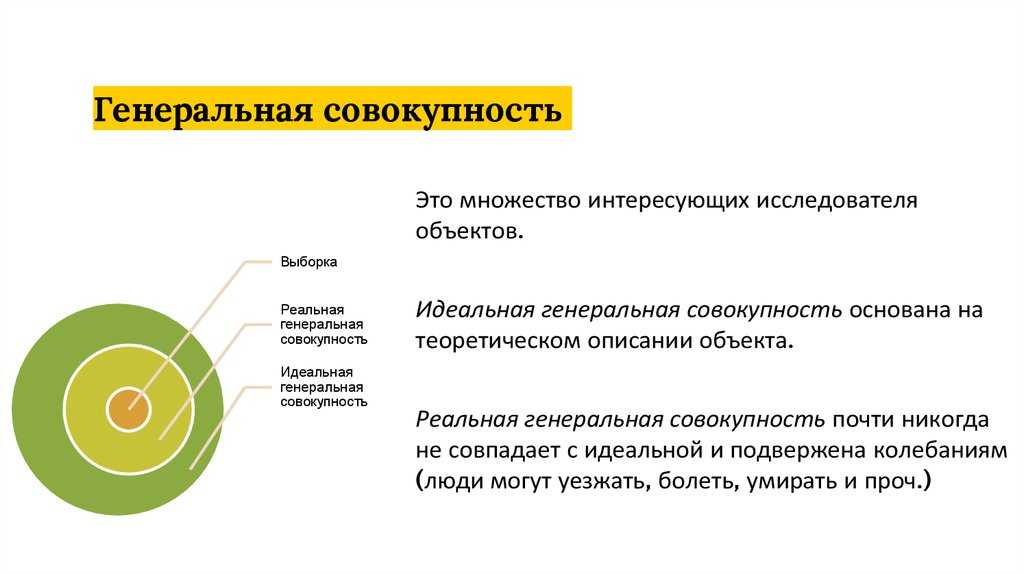
Генеральная совокупность — это множество всех объектов, относительно которых предполагается делать выводы в рамках конкретного исследования. Генеральную совокупность составляют все объекты, которые отвечают всем заранее заданным параметрам.
Почему это важно? Разберем на конкретных примерах
Пример 1
Хотим узнать средний рост у космонавтов, находившихся в космическом полете более 180 дней.
Так как под такое описание подходит небольшая группа людей (а именно космонавты, которые пробыли в полете более 180 дней), мы можем провести исследование с участием всех представителей этого класса. Они и будут составлять генеральную совокупность нашего исследования.
Пример 2
Хотим изучить, какой мультфильм является самым любимым у детей до 5 лет, живущих в Москве.
В данной ситуации абсолютно все дети в возрасте до 5 лет, которые живут в Москве, будут представлять генеральную совокупность для нашего исследования.
Очевидно, что в исследовании из Примера 1 мы можем измерить рост каждого космонавта и получить желаемый результат.
В Примере 2 все становится несколько затруднительнее: теоретически мы, конечно, можем опросить каждого ребенка из Москвы в возрасте до 5 лет, но это сложно реализуемая затея.
Что тогда делать? Можно взять только определенную часть генеральной совокупности, то есть сформировать выборку для исследования, а затем обобщить результаты, полученные на этой выборке, на всю генеральную совокупность.